What is it?Using Python and a Raspberry Pi plus three lines of code you can hack a picture or image and scrap all the text into the console window. The program uses OCR Optical Character Recognition, a technology that enables you to convert different types of documents, such as scanned paper documents, PDF files or images captured by a digital camera into editable and searchable data. This code uses images in a range of file types, jpeg and png.
1. Getting StartedThis is a really easy hack which basically requires three lines of code and a couple of additional libraries. Firstly update your Raspberry Pi:
In the LX Terminal type: sudo apt-get update sudo apt-get upgrade Then install Google's Tessaract OCR software by typing: sudo apt-get install tesseract-ocr 
(tesseract-ocr is a project Google have been working on full details are available here, it contains extra codes and developments)
Next install the Python Wrapper for the Tesseract-OCR software - this basically enables you to program the OCR using Python Code.
In the LX Terminal type using PIP: sudo pip install pytesseract 
The final part is to install the Python Imaging Library PIL sudo apt-get install python-imaging sudo apt-get install python-imaging-tk Then reboot the Pi sudo reboot |
Three Line Hack2. The CodeNow download or create an image which contains text, the two below worked very well. I also tried a screen shot of a website and had about 70% success, there were some random characters and issues.
In the LX Terminal type sudo idle Open a new Python window and add the following code import Image import pytesseract print pytesseract.image_to_string(Image.open('test.png')) Where test is the name of the picture you which to scan, I tried jpg and png and they both worked well. Save the program into the same folder as the pictures and hit F5 to run. It really is that simple! 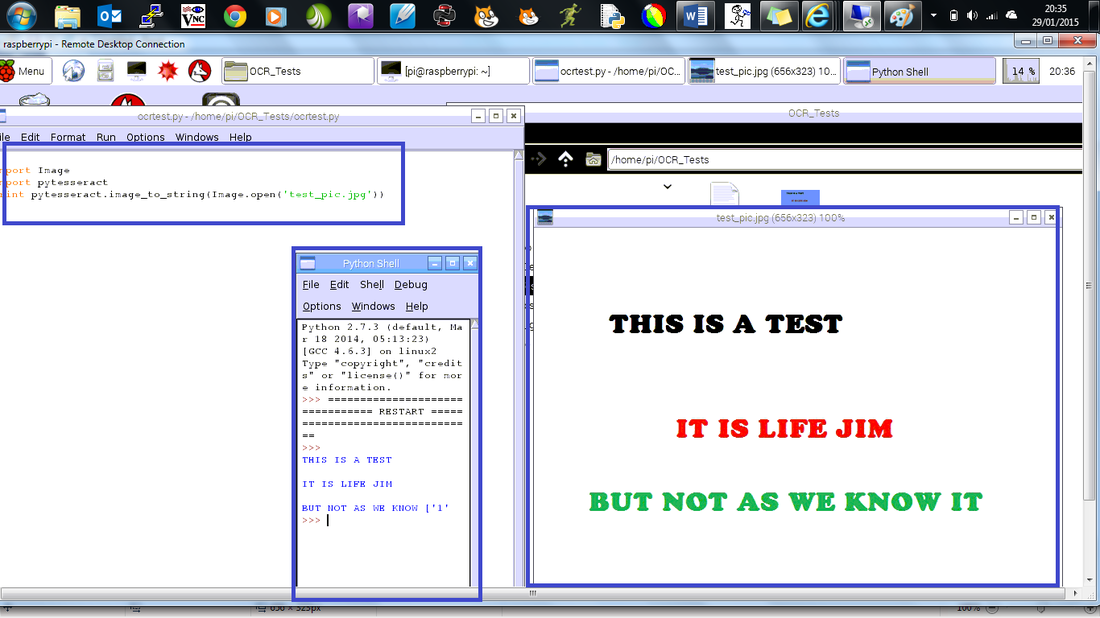
Some other Tesseract-OCR Resource Links:
|
- Home
- Python
- Ras Pi
-
Pi Hardware
- Pi-Hacks
-
Pi-Hacks 2
- The Joker
- Hologram Machine
- Google Vision: Camera Tell
- Yoda Tweets
- Pi Phone
- Darth Beats
- Twitter Keyword Finder
- Crimbo Lights Hack
- Xmas Elf
- Halloween 2016
- Halloween Hack 2015
- Socrative Zombie
- Voice Translation
- The Blue-Who Finder
- GPIO, Twitter
- Pi Chat Bot >
- PiGlow & Email
- Pibrella Alarm System
- SMS with Python >
- Pi-Hacks 3
- Minecraft
- Computing
- Contact Me
- Random Hacks


